| Life
on VRML Island’s getting tough – time to relocate to the mainland
VRML
has developed as an island community with few ties to the Information
Technology mainland. VRML currently lives inside a file and is dependent
on VRML-specific applications for authoring and viewing, isolating
VRML from mainstream users and developers. We submit that VRML should
relocate to the mainland and live inside industry standard databases
as a fully supported complex data type and be supportable wherever
other contemporary data types are supported.
Far
from suggesting that VRML be abandoned, we recommend that the VRML
Island community pack-up, set sail for the mainland, and integrate
themselves into the mainstream.
What’s
needed is:
(1)
Compatibility of VRML, as a complex data type, with suitably extended
SQL (relational and object relational) and ODMG (pure object) database
management systems, meaning that VRML can live inside these databases
just as alphanumeric, image, audio, video, and spatial data do presently.
(2)
Support for integrated VRML in all categories
of development tools: programmatic IDEs for Java, C++, VB, etc.;
application and database development packages and 4GLs; authoring
tools; reporting packages, data mining, data analysis and decision
support tools; monitoring and management environments, etc..
(3)
Browser independence – VRML content renders in Fahrenheit, Java3D,
XML, and other viewers, and ultimately, VRML becomes "Browser Free".
This is not a radical departure for VRML.
Rather, it is the evolution of VRML in alignment
with contemporary IT practices, standards, and architectures.
The
remainder of this paper is presented across six sections.
The
first section, A guided tour of mainland history and attractions,
motivates the journey by surveying the many virtues of the IT mainland
that have evolved over time and compares and contrasts these with
VRML’s progression and it’s nearest neighbors.
The
second section, How the HTML Island community is relocating,
looks toward a neighboring island community as a point of reference
and observes how they have performed their own relocation and integration
into the mainland.
The
primary contention of this paper is then precisely stated in section
three, VRML must be redeployed for the mainland.
General
recommendations for moving in this direction are then offered in
section four, Suggested preparations for relocating to the mainland.
This
is followed by a specific proposal in section five to accomplish
the stated mission, SQL3D - The Ship for the Trip.
Section
six, Enabling a new vision for the future, summarizes the
paper and extends the vision of cyberspace that motivated VRML to
begin with.
|
|
Table of Contents
I.
A guided tour of mainland history and attractions
Virtue
1: Data Independence
Virtue
2: Concurrency
Virtue
3: Distributed Processing
Virtue
4: Distributed Data
Virtue
5: Universality
The
Final Virtue: Users and developers – lots of them!
II.
How the HTML Island community is relocating
III.
VRML must be redeployed for the mainland
IV.
Suggested preparations for relocating to the mainland
V.
SQL3D - The Ship for the Trip
What
is SQL3D?
SQL3D
Origins and Future
SQL3D
Architecture
The
Big Picture
VI.
Enabling a new vision of the future
|
|
The
Information Technology mainland has been evolving in earnest since
the 1960’s and its roots can easily be traced back another 20 years
previous to that. During this half-century or so, IT and Data Processing,
as it was called in the early days, evolved in many directions simultaneously,
several of them intertwined. Each direction brought new benefits,
greater ease of use, more power, reduced cost, additional users
– eclipsing the technologies, architectures, and systems that had
come before.
The
result are 5 major attractions or virtues. Together, these virtues,
and their evolution, form a reference frame against which we can
assess where VRML is today and where it needs to go tomorrow to
enter mainstream Information Technology.
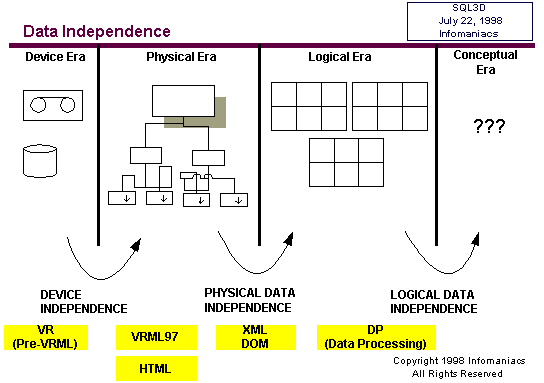
Data
independence concerns the level of abstraction that users and developers
must understand and address when they interact with data. Back in
ancient times (circa 1965) users were forced to confront the details
of physical devices to find and modify data, addressing specific
positions on 9-track tape and specific segments on magnetic drums.
The
concept of a "file" virtualized these hardware devices – one could
request a file by name and the operating system or file manager
would handle the idiosyncratic hardware, shielding the user from
these details. System managers could then restructure or replace
the physical device so long as they maintained the file and remapped
its relationship to the hardware. Files, as virtual data devices,
provided a measure of independence between the physical devices
and the users. This is called physical device independence.
When
we defragment a hard disk today we’re not concerned that our documents
and spreadsheets will get jumbled, a virtue attributable to physical
device independence. As IT matured the file concept grew into the
concept of a database which tracked inter-relationships between
multiple files.
Although
freed from device-specific details, users now had to concern themselves
with the physical structure of databases and the organization of
data within them. Ted Codd’s relational model of data virtualized
the concept of a physical database into a logical database, providing
users, developers, and administrators with a new kind of data independence
– physical data independence.
Users
no longer were required to know the location of a datum within a
database – position was in fact undefined – they merely would request
data by means of its attributes or logical identifier, called a
key. Managers could reorganize the physical layout of data within
the database management system without impacting users or programs.
Users were still required to understand the logical properties of
data and logical relationships in order to address and use the data,
but this too may change as we enter the next era of data independence
– logical data independence.
|
Data Independence
- Interface to data is independent of physical devices and physical
representations
|
|
What
has all this got to do with VRML? Quite a bit! VRML is not the first
step for virtual reality, just its current incarnation. Only several
years ago creating a virtual world meant writing a complex program
in C which would make function calls to specific physical devices
for obtaining input from sensors and gloves and then rendering views
of the virtual world for specific output devices such as HMDs (Head
Mounted Displays).
Part
of the goal of VRML (more specifically a goal of IRIS Inventor and
Open Inventor upon which VRML was based) was to insulate the VR
developer from these device-specific details, hoping in time to
have VRML browsers that supported stereoscopic viewing, 6DOF input
devices, HMDs, even CAVEs. Though support for these have not appeared
in commercial product releases (except for Inventor), VRML itself
successfully divorced the representation of a 3D world from the
devices used to view and interact with it, providing the VR developer
with physical device independence.
But
as we have just seen, the mainland has taken this notion of data
independence much farther, a path that VRML could easily follow.
It’s interesting to note that VRML’s contemporaries, such as HTML,
are no farther along the data independence path.
Though
not commonly understood or appreciated, data independence makes
systems far easier to use and to manage and is an absolute requirement
of mainland technology. VRML still has time to move ahead and provide
users and developers with physical data independence.
Before
moving on to the next attraction we should note in passing how data
processing delivered data independence, for the same techniques
may be useful as we look to instill VRML with greater data independence.
The key was the move away from physical representations towards
more logical representations operating at a higher level of abstraction.
Standard file formats for storing data and their associated physical
access methods (e.g., ISAM and VSAM) gave way to industry standard
logical interfaces (e.g., SQL), making the underlying file formats
irrelevant. Ask yourself who today concerns themselves with directly
addressing a DB2 or an Oracle data file. Just about no one, because
we’ve graduated to accessing all data through a logical interface.
In
the modern world of data independence it’s not the file format that
must be standardized but the logical level interface language!
|
|
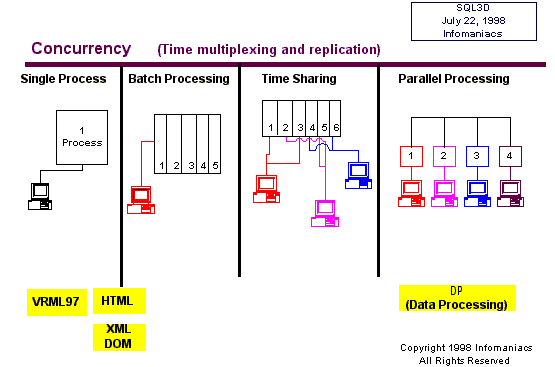
The
next attraction we’ll consider is concurrency, meaning the capacity
for multiple users and/or programs to be reading and writing data
simultaneously without conflict or anomaly. In traditional data
processing this began with the development of batch processing and
scheduled job control, leading to time sharing where multiple users
shared a processor and its peripherals "apparently" at the same
time. Contemporary multiprocessor systems spread the user load not
just over time, as is done with time sharing, but also over space
– across processors.
|
Concurrency
- Multiple users access and update data in a scaleable fashion without
conflict
|
|
Where
is VRML, and for that matter HTML, in this progression? The VRML97
standard is strictly single user, single process, meaning that two
users viewing the same VRML world share absolutely no state – a
change in one copy of the world, via navigation or interaction,
has no effect on any other copy. This places VRML97 at square one
along the concurrency evolution timeline. Two VRML related efforts
do provide some measure of concurrency, however.
The
recently submitted recommended practice for VRML to database connectivity
provides a first step towards concurrency, but it should be mentioned
that concurrency is not its primary aim. In this submission, steered
by Oracle, a VRML scene initially can acquire some of its state
from row and column data stored in a relational database. While
useful, in and of itself this provides no concurrency since two
or more users acquire identical state information initially when
each downloads a copy of a given VRML world based on database values.
However,
the Oracle submission goes further. If an update is made to a database
column from which a VRML world derives attribute information, say
the position of a sphere, then that update is propagated to each
running copy of the VRML world, meaning that the change is made
concurrently to each users’ copy in memory and each user sees the
sphere at the new position. Currently this is unidirectional – the
server can propagate changes to the browser but the browser cannot
make changes to the server.
The
Living Worlds (LW) proposal takes a larger step towards concurrency.
Each LW browser still maintains a copy of the VRML scene, but changes
to the position and orientation of selected scene objects (primarily
avatar representations of concurrent users) are propagated to a
multi-user server, a MUtech in Living Worlds parlance, that then
forwards these to other LW browsers. In this way users become aware
of the other users concurrently within a VRML world and their changing
whereabouts and behaviors.
Where
does this model of concurrency fit in the evolution of mainland
concurrency? Early networked PC database systems, notably Ashton
Tate’s DBase, used a network server’s file i/o to forward a network
copy of database files to each local user, relying on the server’s
file locking to prevent two users from making changes to the same
file at the same time. This "networked" database approach placed
severe limits on file size, number of users, and quickly led to
contention problems. Fortunately, client/server databases made the
PC scene in short order, displacing this ad hoc architecture into
oblivion. LW avoids these issues only by severely restricting the
changes that can concurrently be made.
HTML
makes no concessions to concurrency whatsoever, although plug-ins
and Java applets have extended HTML browsers into the arena of multi-user
chat for some time.
Concurrency
is an important mainland attraction. Single user systems on the
mainland are practically unheard of. Besides, if we want lots of
users using VRML it would help to directly support lots of users
with VRML.
|
|
The
third mainland attraction we encounter is easily the most commonly
known, for its evolution broke through the glass walls of the mainframe
culture, producing client/server computing more than a decade ago
and responsible today for ushering in the era of network computing
-- 3-tier and n-tier architectures.
The
basis of distributed processing is an efficient and effective partitioning
of a task or function into parts that can be distributed to independent
threads, processes, or processors. In the first era all functions
were handled by monolithic programs. For example, a single Cobol
routine would handle data management on specific devices, manipulation
of the data via user requests translated into programs, and data
presentation as printed reports. In time these functions of data
management, manipulation and logic, and presentation were partitioned
into separate processes, though typically executed on the same uniprocessor.
Data
management was distributed by client/server architecture to a server
process while distributing data manipulation logic and presentation
to client processes, thereby better exploiting the processing cycles
idly sitting by on corporate desktops. Today’s n-tier architectures
maintain data presentation on the client where a GUI is best suited
to the task but re-centralize application logic for data manipulation
back to a server, in this case an application server, thereby better
exploiting multiprocessor servers and easing systems management
and software deployment – the network computing movement. Management
of data remains on a back-end database server or legacy system as
it does in the client/server scheme.
Distributed
Processing - Partition application by function and distribute these
to where they work best
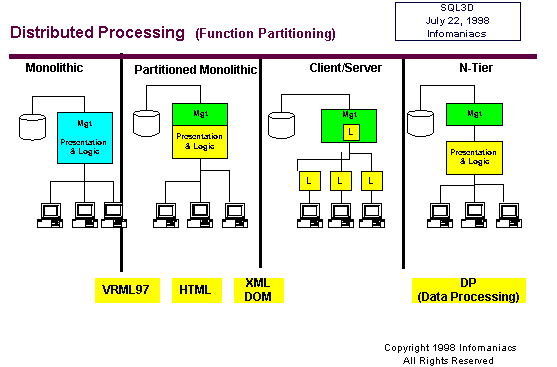
In
passing we note that data independence and distributed processing
co-evolved, for partitioning data management apart from presentation
and application logic enabled file managers and DBMSes to arise,
laying the groundwork for the shift from physical to logical representation
that provides data independence. The two go hand-in-hand.
It
must be emphatically stated that VRML is not client/server. Only
by redefining client/server (redefining in an Orwellian sense) to
mean file server can VRML even begin to be claimed to be client/server.
In reality, a VRML browser is a monolithic application that just
happens to obtain it files from a distributed file system affectionately
known as the Web. The architecture of VRML browsers makes no use
of partitioning – every VRML browser is an island.
The
same cannot be said of HTML as it is deployed en mass. Though inelegant
and clunky, HTML, first by way of CGI and Perl and today through
JavaScript and Java applets has partially entered the client/server
era, and with CORBA and Java RMI, HTML now plays even in the n-tier
era. As HTML’s heir, XML inherently partitions data structure from
data presentation, presaging the client/server web.
With
regard to distributed processing, the VRML Island community is left
behind in XML’s wake. This is unfortunate as distributed processing
is the prevailing architectural paradigm of mainland systems. If
VRML wants to play on the mainland it’s got to become distributed
and leave its monolithic architecture where it belongs – in the
past.
|
|
Perhaps
the least understood of the mainland’s attractions and certainly
the least exploited is data distribution. Least understood because
it means more than the ability to easily move and relocate data
– data distribution implies a level of transparency, where data
can be relocated without functionally impacting users and programs
that interact with the data. As such, data distribution implies
an extended form of physical data independence – independence from
the physical location of data. Notice that this does not claim that
users and programs will see no performance impact from data distribution.
On the contrary, distributing data is sure to improve one user’s
observed performance at the cost of another’s. Performance impact,
yes. Functional impact, no.
Distributed
data with replication is the latest trend. Here, performance sensitive
data is replicated to provide a local copy to multiple groups of
users who are geographically distributed. In the most advanced implementation,
known as multi-master replication, any copy of the replicated data
can be updated and the changes then automatically propagated to
all other copies. Less advanced implementations require all changes
be made on a single copy of the data, the master replicate, or they
forbid updates to replicated data altogether.
Distributed
Data - Distribute data physically while preserving the appearance
that the data remains local
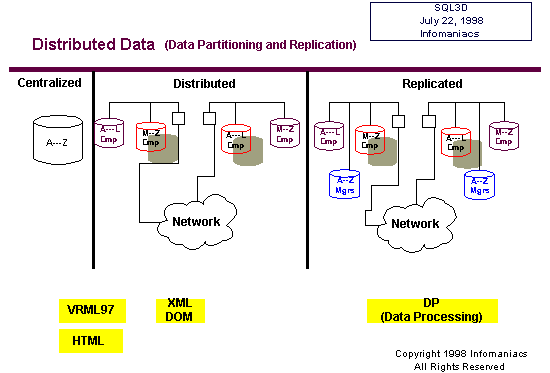
The
greatest limitation to distributed data today is the lack of heterogeneity.
ALL the tables must live in DBMSes from the same vendor to accomplish
the distribution in the diagram above, with the employee table distributed
across two sites and the managers table replicated at both sites.
This will change in time.
By
some stretch of the imagination VRML could be said to offer some
measure of data distribution, providing transparency through the
use of URNs rather than URLs, but this is rudimentary compared with
distributed data as it is discussed in distributed database circles.
HTML fares no better.
Transparent
data distribution with multi-master replication becomes essential
as we build 3D worlds of limitless size and detail (scaleable worlds)
and support multiple users within such worlds – size and ownership
issues will dictate that the worlds are distributed, ease of use
will require location transparency, and performance will mandate
replication.
|
|
Virtue
5: Universality
As
mainland technology evolved, vendors of key components, such as
database management systems, wanted to be all things to all customers.
Handle multimedia data in addition to alphanumeric – no problem.
Manage data integrity and security within the database – we can
do that. Absorb application logic as triggers and stored procedures
– we can do that too! Manage complex data types in addition to simple
values – why didn’t you say so?
Universality
- All required facilities and formats are supported by a coherent
system image
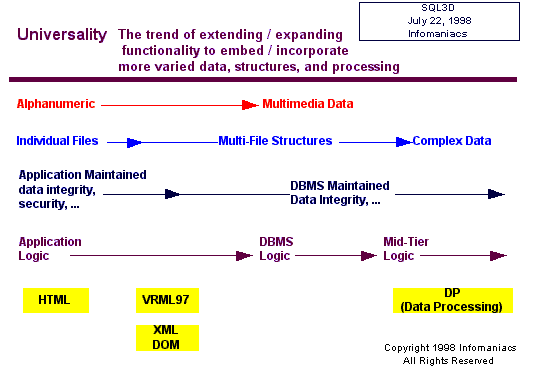
VRML
fares surprisingly well in many of these areas. As the manager of
3D space VRML integrates images, audio, and video, only lagging
in its support for efficiently handling alphanumeric data. VRML’s
event model and script node provide a mechanism for creating cascades
of events and triggering procedures, though lacking an abstracting
method for building and using behavioral components.
In
these regards HTML looks positively anachronistic, an ad hoc assemblage
of fixes and patches to handle the ever expanding demands of users,
rather than a developed architecture.
As
VRML approaches full support for the previous 4 mainland virtues
universality will likely emerge for free. Work must be continued,
however, on the media integration front and with robust support
for live alphanumeric data within VRML scenes.
|
|
Taken
together, these five attractions of the mainland have produced systems
supporting more data accessible by more users thereby
attracting more developers – exactly what VRML needs! One
can ask if these mainland virtues are indeed applicable to VRML.
From the preceding survey it is clear that VRML, as well as HTML
and XML, are on the roadmap of IT, and all have a long way to go
before they become enterprise-class.
VRML
is clearly a presentation technology, and should provide 3D presentation
of data, supporting all the virtues of contemporary IT and forsaking
none. Would insurance companies have jumped on multimedia several
years ago if they couldn’t insure integrity and security of that
new data? Not likely! So VRML, as a presentation technology, must
support the needs of the mainland IT community, and this means interoperating
with systems that exhibit the 5 virtues we’ve just surveyed.
Beyond
presentation, VRML is about managing 3D and even 4D data (3D + time),
something that IT is just beginning to discern on the horizon as
it explores geospatial data and its utility. Ultimately, mainland
IT will need robust support for, and management of, 3D and 4D data.
But to play in this space VRML must subscribe to the 5 virtues and
deliver them to a degree comparable with contemporary IT products
and systems.
We’ve
seen that partitioning both processing and data are key enablers
to achieving the 5 virtues, as is moving from physical representations
and interfaces to logical ones. Now that we’ve surveyed the many
benefits of relocating to the mainland and have a general notion
of how to achieve them it’s time to check out our nearest neighbor,
HTML Island, and see how they’ve progressed on a very similar journey.
|
|
In
the course of our survey of mainland attractions we’ve seen how
the HTML Island community has been gradually migrating to the mainland.
To begin with HTML Island was a lot closer to the mainland than
VRML Island, in that HTML’s data is primarily alphanumeric, the
same as in mainland documents and databases, easing the path to
interoperability.
In
pursuit of these connections the HTML Island community first deployed
ad hoc bridges – CGI, Perl, JavaScript, and ActiveX - initial steps
in passing data between the mainland and HTML Island. Though pestered
with scalability problems these links enabled the mainland to find
value in HTML as a presentation and interface vehicle.
The
rise of Java then established an island subcommunity of commuters,
programs that could move between the mainland and HTML Island. Then
with CORBA and Java RMI came the ability to form strong ties between
Java applets commuting to HTML Island and traditional enterprise
processing running on the mainland – HTML entered the era of distributed
processing with partial client/server and n-tier support.
The
next step for HTML looks to be a near full embrace of mainland IT
– XML (eXtensible Markup Language). XML defines two essential partitions
necessary to integrate into the mainland community. First, "information
presentation" is partitioned from "information structure", making
it possible to manage XML data on a server and distribute XML presentation
to a client. Second, XML partitions content into units smaller than
pages, called elements in XML, which can be accessed individually
and assembled into pages dynamically. Taken together, these two
partitioning schemes make XML content amenable to traditional data
processing techniques and architectures, a necessary step to achieving
the 5 virtues of the mainland.
Is
this really what XML advocates are thinking, managing XML as elements
in databases rather than as documents in operating system files?
The following quotes from Simon St. Laurent's book, XML A Primer,
1998, remove just about any doubt.
p.279
XPointers
This
use of the ID value makes it very easy to subdivide a document into
more manageable chunks with well-structured elements...This makes
it easy to excerpt other documents using links--a feature known
in other systems, notably Ted Nelson's Xanadu, as transclusion...For
this to work really well, file structures will need to change to
avoid making the processing application load the entire document
rather than just the desired chunk. The file system itself would
have to be an XML processor (perhaps even an object database),
storing XML documents as elements rather than as a single file that
must be parsed sequentially. [Emphasis added.]
p.303
XML Servers
The
solution to all these problems is simple, even though it will take
considerable work to implement: servers need to be able to distribute
chunks as well as files.
p.304
Although still complex, carrying a steep learning curve, object-relational
databases are capable of handling precisely these kinds of requests
efficiently. Object-relational databases provide hierarchical (i.e.,
they correspond neatly to XML's nested elements) that can be retrieved,
searched, and processed quite easily...Inso, a participant in the
XSL proposal and DOM working group, uses an object-relational database
as the foundation for its Dynabase HTML site management tool, for
example.
It’s
clear from these passages that Simon St. Laurent thinks XML content
should reside as elements in mainland databases and systems. But
then how do these XML elements, living in databases, get reassembled
into wholes that XML browsers can view? Simon continues.
p.307
Anatomy of a Browser
Our
all-powerful parser serves to create only an initial state for the
browser, after which the element tree it creates may be modified,
reorganized, or even rebuilt.
To
my mind, this gets us damn close to having the XML data at the client,
the element tree, living in a client-side database or client object
data cache, where XML elements can be inserted, updated, queried,
deleted, and generally reorganized. The DOM (Document Object Model)
provides an API into the XML element tree, portending the future
existence of such a client-side object data cache. Simon is probably
limited, though, in thinking that the XML parser would create an
"initial state" – why parse a page into elements for the initial
state when these too can be selected from their back-end database
residence. Either way, how does the browser-as-client present each
element type that it may fetch from some mainland database?
p.312
Breaking Down the Browser
In
this scenario, the browser is reduced to a communications engine
and a parser, along with a framework that allows different applications
to communicate and modify the element tree...In this possible browser
future, the presentation and interface aspects of the browser would
be taken over by other applications (even miniapplications) that
process elements. They would have their own presentation and interface
structures, which the "browser" might continue to coordinate...In
this model, much of the functionality that used to be in the browser
is distributed across applications devoted to the processing of
particular elements. They can all share a parser, a communications
engine, and the same element tree, but the browser as a unit is
unnecessary. The parser, engines, and element tree interface become
browser services, rather than a distinct unit.
Simon
St. Laurent illustrates this architectural transformation in browsers
with the diagrams below. First we see the basic browser structure
of today with its monolithic presentation engine.
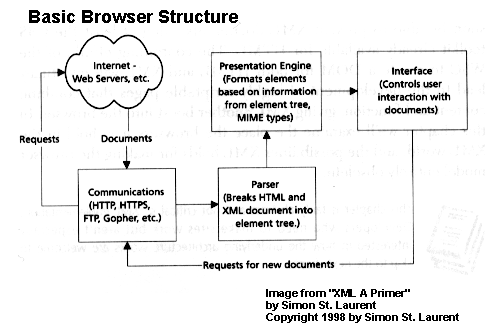
Next
we see Simon St. Laurent’s depiction of where browsers could be
headed. Notice the miniapplications, as he calls them, that handle
the presentation of specific element types in the element tree.
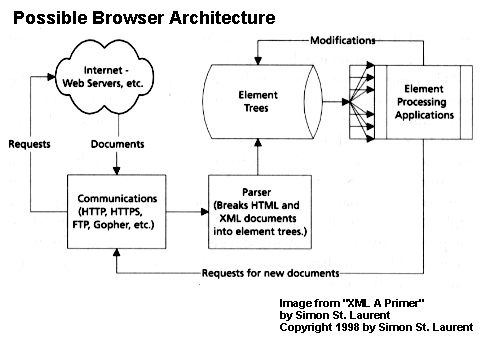
By
Simon St. Laurent’s analysis, the concept of an XML browser itself
may disappear, replaced by an open framework for clients that provide
parsing, data management, and communication services, and into which
content-specific presentation/interface applications would dynamically
link. Simon’s architecture is very good as far as it goes, but we
can update this architecture quite easily to bring it in alignment
with current IT practice. Take the icon for the Element Trees and
rotate it counterclockwise 90 degrees – you’ve got the element trees
now in a local database. Take the parser and make it an import/load
facility for the database. Expand the Communications engine into
a full fledged Object Request Broker. And if desired, drop the whole
thing into a Java VM sandbox as shown next.
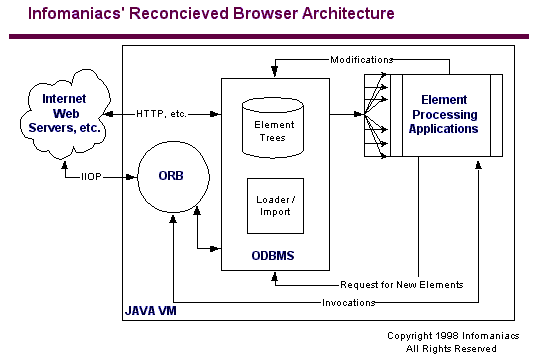
In
such a browser future could VRML be one of these content types,
living in databases? And what would that mean for the future of
VRML browsers? Would they disappear, replaced by VRML rendering
and interface mini-applications that link into XML client frameworks?
This would certainly pave the wave for VRML to become "browser free".
We’ll return to these questions later. What we need to do now is
clearly state what VRML must become to integrate into the IT mainland
community and thereby offer its many attractions.
|
|
We’ve
identified a handful of key concepts from our general survey of
mainland IT’s march forward as well as HTML’s move to the mainland.
For VRML to relocate to the mainland and integrate tightly with
the IT community two general objectives must be achieved:
- VRML
should utilize an effective partitioning between information presentation
and information management (as IT has for a decade and XML is
doing today).
- The
separated partitions must be re-connected. A high-level (logical)
public interface between partitions is essential -- DBMSes progressed
from standardized file formats (e.g. VSAM) to standardized, high
level, declarative interfaces (e.g. SQL) -- VRML must do the same.
The
environment that provides the requisite partitioning and the public
interfaces between partitions need not be created from scratch,
it already exists – it’s the realm of mainland client/server and
network computing systems, supported by relational, object/relational,
and pure object database management systems and distributed object
infrastructures. Achieving these goals does not require a wholesale
redesign and redevelopment of VRML. What’s needed is a redeployment,
picking up VRML as it is and deploying it in the mainland environment.
In the process VRML and its capabilities will be transformed. Let’s
get real clear on where VRML is currently in this regard and where
we want to take it, the destination.
The
VRML standard currently specifies:
- a
physical-level representation language
- physical
interfaces (Script node and EAI)
- a
file format
- normative
behavior and conformance requirements
A
redeployed VRML standard would specify:
- VRML
schemas for ODBMSes, RDBMSes, ORDBMSes, etc.
- logical-level
languages/interfaces as extensions to transactional data languages
(SQL3, ODMG, etc.)
- Physical
interfaces (for backward compatibility)
- a
file format
- a
visual/behavioral ontology (unambiguously associating user experience,
e.g., "red", with syntactic VRML expressions, e.g., (1,0,0))
The
first two of these require elaboration. Where VRML currently specifies
a format for representing a scene as structured ASCII text, the
redeployed VRML specification would define how a scene is represented
in commercial database systems. For relational databases it may
mean specifying tables that maintain nodes of a certain type and
their fields as well as tables to represent the transformation hierarchy.
For object databases the mapping will likely be more direct, and
for object/relational somewhere in-between. This amounts to, at
minimum, a VRML schema for each DBMS type.
Each
DBMS type supports a standard language for querying and modifying
its data. SQL is the best known of these languages, a high-level
interface to relational data. SQL (and languages for pure object
databases) would be extended as needed to represent the structural
and behavioral aspects of VRML scenes. These efforts would be focused
on SQL3 for relational data, a work in progress to extend SQL with
object capabilities. It is entirely possible (indeed expected) that
pure object data languages (the ODMG’s (Object Data Management Group)
OQL and ODL) will require little if any extension.
The
remaining directives are aimed at backward compatibility (preserving
current physical interfaces such as the EAI and the script node
for Java and ECMAscript), portability (a VRML file format), and
conformance (extending the present conformance work into a full
fledged visual/behavioral ontology).
|
- Several
words of guidance are offered as we prepare for the trip ahead
– the redeployment of VRML.
- Real
Time Interactive 3D applications like VRML have unique performance
requirements for data presentation - some data management must
be done at the client. Displaying text and simple animations at
a client is not a challenging prospect. Displaying arbitrary 3D
worlds at 30fps where the user is unrestricted in their roaming
and navigation is a different animal altogether, requiring that
scene data, at least that within and near the viewing frustum,
be kept close to, in fact a part of, the graphics rendering pipeline.
This means that scene data cannot be entirely relegated to a remote
server process.
- 3D
vendors should be handling data presentation because they understand
rendering. They should not be building full-fledged 3D databases
because they lack the expertise. Building robust database management
systems requires 1000’s of man years of research, design, and
development. Even upstarts within the data management community
rarely succeed, as competitors of Oracle and IBM know all too
well. It is a complete waste of time, effort, and money for vendors
with expertise in 3D rendering and manipulation to even try to
recreate contemporary database functionality, providing data independence,
concurrency, distributed processing, distributed data, and universality.
No attempt should be made to extend present VRML scene managers,
found in VRML browsers, into contemporary database systems. This
should be bought or licensed.
- DBMS
vendors should be handling data management because they understand
storage, retrieval, and transactions. They should not be building
3D clients because they lack the expertise. This is the corollary
of the preceding suggestion – expertise in 3D rendering takes
time and expertise that the mainland and its vendors do not possess.
DBMS vendors should buy or license 3D rendering technology from
3D vendors.
- These
recommendations when taken together suggest a partnering between
3D vendors and DBMS vendors, an exchange or cross-licensing of
technologies so to speak.
|
|
The
5 virtues provide abundant motivation for VRML’s redeployment to
the mainland. XML as a work in progress outlines a possible path.
We have clearly stated what VRML needs to become, and have circumscribed
rough principles to guide us on the voyage. What remains is finding
the right vehicle to take VRML to the mainland and structure it’s
integration. SQL3D is that vehicle, the ship for the trip.
SQL3D
is Infomaniacs’ technical architecture and schemata that builds
on and extends industry standards to enable applications using 3D
data to interoperate with each other, support multiple users in
sharing 3D data without conflict, seamlessly integrate 3D, 2D, multimedia,
temporal, and alphanumeric data, and exploit the strengths of distributed
data and object management.
SQL3D
integrates real-time 3D content into traditional data management
systems and application platforms and provides such content with
persistence, multi-user concurrency and consistency, durability,
security, scalability, and distributivity.
SQL3D
applications and viewers manage 3D content in a locally cached,
distributed heterogeneous federation of object / object relational
databases supporting strategic standards from 3D, database management,
and object management. Applications supporting SQL3D become
interoperable and multi-user.
SQL3D Highlights
- 3D
as a fully supported data type in databases, applications,
and transactional system
|
- Integrates
3D data with 2D, spatial, temporal, multimedia, and alphanumeric
data
|
- Supports
application interoperability: "3D to 3D" and "3D to Conventional"
|
- 3D
Multiuser Concurrency and Consistency
|
- Persistence,
Recovery, and Security of 3D data
|
- Scalability
and Distributivity of 3D data
|
- Can
host varied 3D representations: VRML, Fahrenheit, Java3D,
Open Inventor, IRIS Performer
|
Infomaniacs
has been at the forefront of inter-disciplinary research, with foci
in human-computer interface, intelligence augmentation, AI knowledge
representation, semantic data modeling, and DBMS architecture and
design. In 1983 the principals of Infomaniacs began a long term
research project to enable humans to more fully exploit vast and
varied collections of data, information, media, and real world knowledge.
This work included research in interface as well as in representation
and retrieval. Along the way we sought both data-driven 2D multimedia
authoring environments as well as tools for building 3D interfaces.
In
1993 we discovered Open Inventor from SGI, a C++ toolkit that met
many of our desires. In 1994, as part of researching and writing
PC Magazine’s first feature on Virtual Reality we interviewed Rikk
Carey, the father of Open Inventor. SQL3D had its genesis here,
as we first began to contemplate using robust database management
systems to manage 3D scene data. Ironically, this was the very same
moment in time when VRML came into existence, based on Open Inventor.
The
notion of managing 3D scene data in a DBMS slowly percolated on
a back burner for several years under the name "3D 4GL", an acronym
for 3D 4th Generation Language, a reference to a desire
to program virtual worlds using a suitably extended, very high-level,
transactional data language. In 1997 we surveyed many working groups
at the VRML 97 symposium in Monterey California. What we found were
many common goals across the groups, but with as many redundant
approaches to achieving those goals as there were working groups.
In response we informally initiated the VRML Object Management working
group to address these common objectives in a common way.
At
about the same time we became quite hopeful when Netscape released
Communicator 4.0 replete with a VRML 2.0 browser, an Object data
cache, and a CORBA Object Request Broker. It certainly seemed that
someone at Netscape was thinking in the same architectural terms
that we were. Perhaps Netscape would do the work for us. Months
later, seeing no real progress at Netscape, we began talking privately
with key people in the VRML community about our 3D 4GL ideas, having
extended the concept and renamed it SQL3D.
As
for the future, SQL3D is currently a foundational component of a
Raytheon proposal for DARPA’s "Command Post of the Future".
|
|
SQL3D
Architecture
The
architecture of SQL3D is quite straightforward, as is represented
symbolically below. A 3D scene is distributed across a database
federation consisting of DBMSes of varying types and from multiple
vendors. The scene data is maintained within this federation using
schemas appropriate for each DBMS type and vendor implementation.
Connecting
these DBMSes together into a federation as well as connecting SQL3D
clients to the federation is a real time (possibly soft or hard
real time) object infrastructure, here depicted using Infomaniacs’
ioFABRICTM based on real time CORBA and providing federation-wide
transparent data distribution, QoS, multicast support, and controlled
payload downscaling.
Data
and object caches are distributed throughout the federation as required
for performance in addition to special purpose application servers
that handle optimization, tessellation of higher order surfaces,
simplification, decimation, and mediation.
Each
SQL3D client, which can be a viewer or a special purpose application,
maintains an in-memory scene object cache using a commercial ODBMS.
A SQL3D client also incorporates an Object Request Broker to connect
it into the federation via the fabric.
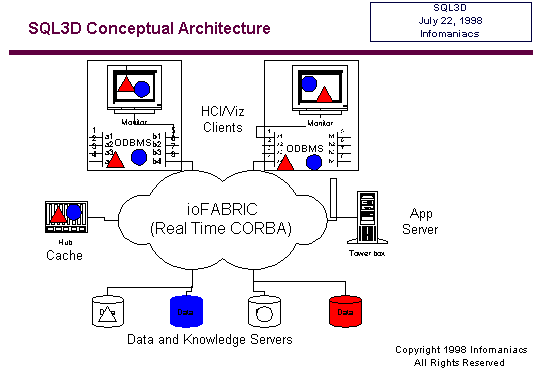
Overall,
the clients see what appear to them as atomic 3D scene elements.
Appearances can be deceiving, however, as these "atomic" 3D scene
elements, the red cone and the blue sphere, actually derive their
state from various databases and knowledge bases in the federation,
with color attribution coming from two sources and shape attribution
coming from two different sources. Scene data can be seen cached
both locally at the client's as well as in federation caches for
performance.
Multiple
users interact fully with all elements in the scene (as allowed
by security permissions), protected against inconsistency by concurrency
mechanisms in the federation and the local client-side object caches.
All scene data is persistent, durable and recoverable, secure, scalable,
distributed, free of physical data dependencies, and interoperable
with data from a wide panoply of types.
What
are SQL3D clients and how do you build one? The following illustration
shows two variations on a theme.
The
Statically Replicated version is intended for developers
of applications based on a scene graph level 3D API, such as Fahrenheit,
Java3D, Open Inventor, and IRIS Performer. The developer runs their
source code for a 3D application through the SQL3D precompiler which
installs a "redirector" that bi-directionally replicates all changes
between the 3D API’s scene graph and a SQL3D in-memory object data
cache which is part of the SQL3D core. The developer may then wish
to extend their application to exploit SQL3D’s capabilities. This
way developers can easily add SQL3D capabilities to new and existing
3D applications.

In
the second variation an existing application (based on a scene graph
level 3D API) is dynamically extended with the SQL3D core,
either replicating the 3D API’s scene management (as above) or replacing
it. This means that applications "in the field" can instantly benefit
from many of SQL3D’s capabilities through defaults (full exploitation
requires that the application is SQL3D aware, meaning explicit control
over transactions, locking, etc.). While there are several methods
of dynamically extending a 3D API in the field it should be noted
that some 3D APIs are far more amenable to dynamic extension than
others.
It
is by way of dynamic extension that we can transform viewers supporting
Fahrenheit, for example, into SQL3D viewers. Applied to VRML this
provides "browser independence", meaning that many 3D viewers can
be transformed at run time to render and navigate VRML content.
Ultimately it is hoped that vendors of scene graph level 3D APIs
can be persuaded to incorporate SQL3D directly in their toolkits
providing all the mainland virtues to their customers right out
of the box.
It’s
worth mentioning that SQL3D viewers can be constructed using either
Static Replication or Dynamic Extension.
Next
we look inside the SQL3D core. The primary components are an ODBMS
(Object Data Base Management System) and an ORB (Object Request
Broker). The ORB is the distributed communications engine. The ODBMS
maintains an object cache in-memory and can also save to disk as
required (e.g., for stand-alone viewers and applications that are
not connected to a federation). Mini applications handle tasks such
as loading (called parsing in XML circles), exporting (writing operating
system files), intelligent pre-fetch and look-ahead to keep the
cache filled with scene data likely to be viewed in the near future,
general utilities, and other functions.
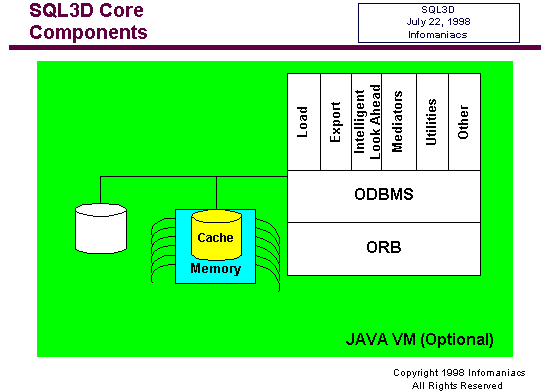
All
of these components can optionally be run as Java components within
a Java Virtual Machine and constitute a very light load from both
local footprint and download perspectives. How light is very light?
A CORBA ORB written in Java can take up as little as 60k, and an
ODBMS written in Java as little as 450k. This opens the door for
a SQL3D application or viewer being downloaded as components as
needed and then dynamically assembled in much the same way as Simon
St. Laurent writes about possible future XML browsers. Applied to
VRML this architectural concept would make VRML "browser free",
no longer reliant on an installed base of VRML browsers in order
to have users. All that’s missing are lightweight, small footprint
rendering engines that can be downloaded on demand. Anyone who was
present at the Siggraph 98 "Web 3D Roundup" likely saw Ken
Perlin’s Java-based rendering engines that downloaded on-demand.
These could well point to the future architecture of 3D client applications.
The
next diagram illustrates, in a relative manner, when various levels
of SQL3D functionality can be deployed. Eventually, mobile components
become practical, making all other issues disappear. Until that
time we begin by deploying SQL3D viewers much as we deploy HTML
and VRML browsers today. Shortly thereafter we support developers
with SQL3D Precompilers to easily transform their applications into
SQL3D applications. Next we offer dynamic extension which transforms
3D applications and viewers in-the-field into SQL3D applications
and viewers. Eventually 3D applications support SQL3D integrally.

Notice
on the lower portion of the diagram that the timeframe between stand-alone
single user SQL3D and distributed multiuser SQL3D is quite short.
The lengthy delay shows up waiting for federated multiuser scenes,
meaning scenes that are distributed across multiple types of DBMSes
and DBMS implementations from multiple vendors. This hold-up has
actually nothing to do with 3D and everything to do with DBMSes.
Currently, if you want to transparently distribute data with replication
you have to do it with all your DBMSes from the same vendor. This
limitation too will go away in time as DBMS vendors support heterogeneous
distributed operations via standardized distributed object infrastructures
like CORBA.
|
|
The
Big Picture
At
last we see the big picture, where SQL3D brings together the 3D
community and the data and object communities. Think of VRML as
a schema inside of SQL3D and you get an idea of the extensive interoperability
VRML will gain through SQL3D as well as the developer seats and
user eyeballs.
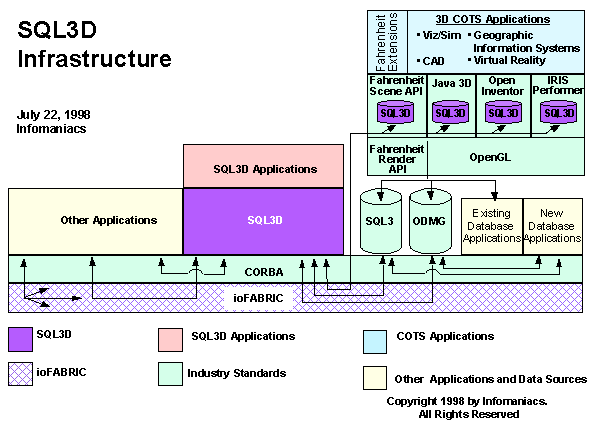
SQL3D
provides VRML with a straight and direct path to relocate to the
mainland and integrate with the IT community living there. This
will put VRML in front of all classes of developers, not just the
tiny subset already exploring 3D authoring tools. And it puts VRML
in front of users of all types of applications – wherever data is
found. VRML even becomes far less reliant on an installed base of
VRML browsers. Coupled with a revolution in web browser architecture,
the dynamic browser framework architecture we looked at in section
II, VRML could conceivably become "browser free", and therefore
be available and accessible to all.
|
|
VRML
needn’t become stranded on a desert island. By redeploying VRML
to the mainland with SQL3D, VRML will finally deliver on the promises
that its creators set out for it. But even more is possible. The
entire computing landscape is in flux. Desktops will not make sense
forever. The time is approaching when unimaginable processing power
and knowledge will exist out on the computing fabric. Embedded systems
and wearable interfaces will provide a connection to the fabric
24x7x365 wherever we are and whatever we’re doing. The web and virtual
worlds won’t be something apart from reality – they’ll be integrated
with reality into a grand HyperReality where information and knowledge
is what’s ubiquitous, not computing – information everywhere and
within everything.
In
this future only a 3D + time interface makes any sense, as physical
reality becomes the interface into virtual reality and virtual reality
augments and interfaces us with physical reality. 3D will then structure
all types of knowledge, media, and information and must be best
buddies with them all. This is the future that demands that VRML
and 3D integrate with mainland IT right down to the very foundations.
If you've read this far...
please contact me and let me know what you think or what questions
you have!
Erick Von Schweber
To
Contact me about SQL3D send mail to sql3d@infomaniacs.com
Copyright
(c)1998 by Infomaniacs. All Rights Reserved.
|
|